Alibaba Cloud เพิ่ม LLM เพื่อรองรับชุมชนโอเพ่นซอร์ส

- อาลีบาบาคลาวด์โอเพ่นซอร์สรุ่นพารามิเตอร์ 72 พันล้านและ 1.8 พันล้านของรุ่นรากฐาน Tongyi Qianwen
- ดาวน์โหลด LLM แบบโอเพ่นซอร์สรวม +1.5 ล้านครั้งบน ModelScope, Hugging Face ตั้งแต่เดือนสิงหาคม
Alibaba Cloud กล่าวเมื่อวันจันทร์ว่าได้สร้างโมเดลภาษาขนาดใหญ่สองโมเดล และโมเดลที่เข้าใจเสียงที่พร้อมใช้งานอย่างอิสระ เนื่องจากดูเหมือนว่าจะสร้างคลาวด์ที่เปิดกว้างที่สุดในยุค AI
บริษัทคลาวด์คอมพิวติ้งกำลังเปิดให้เข้าถึงเวอร์ชันพื้นฐานที่เป็นเอกสิทธิ์ของบริษัท Tongyi Qianwen รุ่นที่มีพารามิเตอร์ 72 พันล้านพารามิเตอร์และ1.8 พันล้านพารามิเตอร์
นอกจากนี้ ยังทำให้ LLM หลายรูปแบบใช้งานได้ฟรีมากขึ้น ซึ่งรวมถึงQwen-AudioและQwen-Audio-Chatซึ่งเป็นโมเดลการทำความเข้าใจเสียงที่ได้รับการฝึกอบรมล่วงหน้า และเวอร์ชันที่ได้รับการปรับแต่งการสนทนาเพื่อวัตถุประสงค์ในการวิจัยและเชิงพาณิชย์
โครงการริเริ่มนี้ช่วยให้ธุรกิจทุกขนาดสามารถใช้ประโยชน์จาก LLM เพื่อสร้างโซลูชันที่ปรับให้เหมาะสม ณ ขณะนี้ Alibaba Cloud ได้สนับสนุน LLM ด้วยพารามิเตอร์ตั้งแต่ 1.8 พันล้าน, 7 พันล้าน, 14 พันล้านถึง 72 พันล้าน รวมถึง LLM หลายรูปแบบที่มีความเข้าใจด้านภาพ และเสียง
“การสร้างระบบนิเวศแบบโอเพ่นซอร์สถือเป็นสิ่งสำคัญในการส่งเสริมการพัฒนา LLM และการสร้างแอปพลิเคชัน AI เราปรารถนาที่จะกลายเป็นคลาวด์ที่เปิดกว้างที่สุด และทำให้ทุกคนสามารถเข้าถึงความสามารถด้าน AI เชิงสร้างสรรค์ได้” โจว จิงเหริน ซีทีโอของ Alibaba Cloud กล่าว
ครอบครัวของ LLM
โดยทั่วไปการปรับขนาดโมเดลภาษาขนาดใหญ่ที่ได้รับการฝึกอบรมล่วงหน้าจะนำไปสู่ประสิทธิภาพที่สูงขึ้น แต่การฝึกอบรมและการรันโมเดลขนาดใหญ่นั้นต้องใช้ทรัพยากรในการคำนวณที่มากขึ้น
ด้วยเหตุนี้ Alibaba Cloud จึงได้โอเพ่นซอร์ส LLM พารามิเตอร์ 1.8 พันล้าน Qwen-1.8B ซึ่งได้รับการปรับให้เหมาะกับอุปกรณ์ขนาดเล็ก และเสนอตัวเลือกที่คุ้มค่ามากขึ้นสำหรับการวิจัย เนื่องจากต้องใช้พลังการประมวลผลน้อยกว่า จึงสามารถทำงานได้บนโทรศัพท์มือถือที่มีทรัพยากรในการคำนวณและหน่วยความจำน้อยกว่าเซิร์ฟเวอร์คลาวด์อย่างมาก นอกจากนี้ยังหมายความว่าแอปพลิเคชันที่ขับเคลื่อนด้วย LLM ยังคงสามารถทำงานได้โดยมีการเชื่อมต่อเครือข่ายที่จำกัดหรือไม่มีเลย
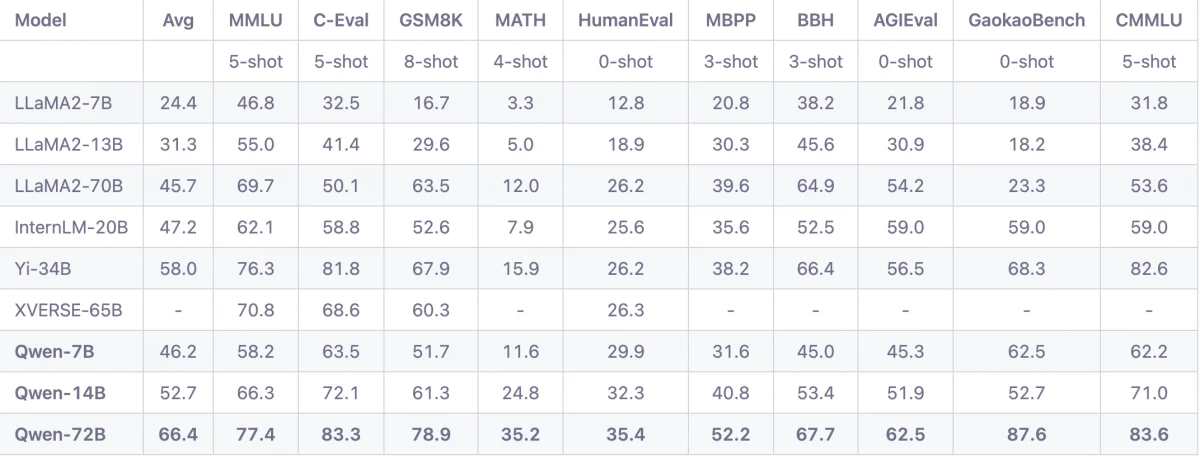
ขณะเดียวกัน Alibaba Cloud กล่าวว่า Qwen-72B ซึ่งมีพารามิเตอร์ 7.2 หมื่นล้านพารามิเตอร์ มีประสิทธิภาพเหนือกว่าโมเดลโอเพ่นซอร์สหลักๆ อื่นๆ เทียบกับเกณฑ์มาตรฐาน 10 รายการ รวมถึงเกณฑ์มาตรฐาน Massive Multi-task Language Undering ที่วัดความแม่นยำของมัลติทาสก์ของโมเดล HumanEval ที่ทดสอบการสร้างโค้ด ความสามารถและ GSM8K ซึ่งเป็นมาตรฐานในการแก้ปัญหาทางคณิตศาสตร์
โมเดลนี้ยังมีประสิทธิภาพเหนือกว่าเมื่อเล่นตามบทบาทและในการถ่ายโอนรูปแบบภาษา ซึ่งเป็นหัวใจสำคัญของการสร้างแชทบอทส่วนบุคคล
ผลักดันหลายรูปแบบ
นอกจากนี้ Alibaba Cloud ยังมีความก้าวหน้าในการบูรณาการความหลากหลายรูปแบบเข้ากับ LLM ของตน นั่นคือความสามารถในการประมวลผลข้อมูลอื่นที่ไม่ใช่ข้อความลงใน LLM
มีโอเพ่นซอร์สโมเดล Qwen-Audio และ Qwen-Audio-Chat เพื่อการวิจัยและเชิงพาณิชย์
Qwen-Audio สามารถเข้าใจข้อความและเสียง รวมถึงคำพูดของมนุษย์ เสียงที่เป็นธรรมชาติ และดนตรี สามารถประมวลผลเสียงได้มากกว่า 30 งาน เช่น การถอดเสียงหลายภาษา การแก้ไขคำพูด และการวิเคราะห์คำบรรยายเสียง เวอร์ชันที่ได้รับการปรับแต่งการสนทนาอย่างละเอียดสามารถตรวจจับอารมณ์และน้ำเสียงในคำพูดของมนุษย์ได้
การผลักดันต่อเนื่องหลายรูปแบบต่อยอดมาจากความคิดริเริ่มก่อนหน้าของ Alibaba Cloud ในการใช้ โมเดล ภาษาวิสัยทัศน์ขนาดใหญ่ Qwen-VL แบบโอเพ่นซอร์ส และเวอร์ชันแชท Qwen-VL-Chat ที่สามารถเข้าใจข้อมูลภาพและดำเนินงานด้านภาพได้
โมเดล LLM แบบโอเพ่นซอร์ส ซึ่งรวมถึง Qwen-7B, Qwen-14B และ Qwen-VL รวมถึงเวอร์ชันที่ได้รับการปรับแต่งการสนทนา ได้รับการดาวน์โหลดรวมแล้วมากกว่า 1.5 ล้านครั้งบนชุมชนโมเดล AI แบบโอเพ่นซอร์สของ Alibaba Cloud ModelScope และ Hugging Face ตั้งแต่เดือนสิงหาคม ตามข้อมูลล่าสุดจาก Alibaba Cloud
คุณอาจชอบเนื้อหานี้




เลือกชมสินค้ามากมาย และให้เราสั่งซื้อสินค้าให้คุณ
เนื้อหายอดนิยม



Alibaba Cloud เพิ่ม LLM เพื่อรองรับชุมชนโอเพ่นซอร์ส

- อาลีบาบาคลาวด์โอเพ่นซอร์สรุ่นพารามิเตอร์ 72 พันล้านและ 1.8 พันล้านของรุ่นรากฐาน Tongyi Qianwen
- ดาวน์โหลด LLM แบบโอเพ่นซอร์สรวม +1.5 ล้านครั้งบน ModelScope, Hugging Face ตั้งแต่เดือนสิงหาคม
Alibaba Cloud กล่าวเมื่อวันจันทร์ว่าได้สร้างโมเดลภาษาขนาดใหญ่สองโมเดล และโมเดลที่เข้าใจเสียงที่พร้อมใช้งานอย่างอิสระ เนื่องจากดูเหมือนว่าจะสร้างคลาวด์ที่เปิดกว้างที่สุดในยุค AI
บริษัทคลาวด์คอมพิวติ้งกำลังเปิดให้เข้าถึงเวอร์ชันพื้นฐานที่เป็นเอกสิทธิ์ของบริษัท Tongyi Qianwen รุ่นที่มีพารามิเตอร์ 72 พันล้านพารามิเตอร์และ1.8 พันล้านพารามิเตอร์
นอกจากนี้ ยังทำให้ LLM หลายรูปแบบใช้งานได้ฟรีมากขึ้น ซึ่งรวมถึงQwen-AudioและQwen-Audio-Chatซึ่งเป็นโมเดลการทำความเข้าใจเสียงที่ได้รับการฝึกอบรมล่วงหน้า และเวอร์ชันที่ได้รับการปรับแต่งการสนทนาเพื่อวัตถุประสงค์ในการวิจัยและเชิงพาณิชย์
โครงการริเริ่มนี้ช่วยให้ธุรกิจทุกขนาดสามารถใช้ประโยชน์จาก LLM เพื่อสร้างโซลูชันที่ปรับให้เหมาะสม ณ ขณะนี้ Alibaba Cloud ได้สนับสนุน LLM ด้วยพารามิเตอร์ตั้งแต่ 1.8 พันล้าน, 7 พันล้าน, 14 พันล้านถึง 72 พันล้าน รวมถึง LLM หลายรูปแบบที่มีความเข้าใจด้านภาพ และเสียง
“การสร้างระบบนิเวศแบบโอเพ่นซอร์สถือเป็นสิ่งสำคัญในการส่งเสริมการพัฒนา LLM และการสร้างแอปพลิเคชัน AI เราปรารถนาที่จะกลายเป็นคลาวด์ที่เปิดกว้างที่สุด และทำให้ทุกคนสามารถเข้าถึงความสามารถด้าน AI เชิงสร้างสรรค์ได้” โจว จิงเหริน ซีทีโอของ Alibaba Cloud กล่าว
ครอบครัวของ LLM
โดยทั่วไปการปรับขนาดโมเดลภาษาขนาดใหญ่ที่ได้รับการฝึกอบรมล่วงหน้าจะนำไปสู่ประสิทธิภาพที่สูงขึ้น แต่การฝึกอบรมและการรันโมเดลขนาดใหญ่นั้นต้องใช้ทรัพยากรในการคำนวณที่มากขึ้น
ด้วยเหตุนี้ Alibaba Cloud จึงได้โอเพ่นซอร์ส LLM พารามิเตอร์ 1.8 พันล้าน Qwen-1.8B ซึ่งได้รับการปรับให้เหมาะกับอุปกรณ์ขนาดเล็ก และเสนอตัวเลือกที่คุ้มค่ามากขึ้นสำหรับการวิจัย เนื่องจากต้องใช้พลังการประมวลผลน้อยกว่า จึงสามารถทำงานได้บนโทรศัพท์มือถือที่มีทรัพยากรในการคำนวณและหน่วยความจำน้อยกว่าเซิร์ฟเวอร์คลาวด์อย่างมาก นอกจากนี้ยังหมายความว่าแอปพลิเคชันที่ขับเคลื่อนด้วย LLM ยังคงสามารถทำงานได้โดยมีการเชื่อมต่อเครือข่ายที่จำกัดหรือไม่มีเลย
ขณะเดียวกัน Alibaba Cloud กล่าวว่า Qwen-72B ซึ่งมีพารามิเตอร์ 7.2 หมื่นล้านพารามิเตอร์ มีประสิทธิภาพเหนือกว่าโมเดลโอเพ่นซอร์สหลักๆ อื่นๆ เทียบกับเกณฑ์มาตรฐาน 10 รายการ รวมถึงเกณฑ์มาตรฐาน Massive Multi-task Language Undering ที่วัดความแม่นยำของมัลติทาสก์ของโมเดล HumanEval ที่ทดสอบการสร้างโค้ด ความสามารถและ GSM8K ซึ่งเป็นมาตรฐานในการแก้ปัญหาทางคณิตศาสตร์
โมเดลนี้ยังมีประสิทธิภาพเหนือกว่าเมื่อเล่นตามบทบาทและในการถ่ายโอนรูปแบบภาษา ซึ่งเป็นหัวใจสำคัญของการสร้างแชทบอทส่วนบุคคล
ผลักดันหลายรูปแบบ
นอกจากนี้ Alibaba Cloud ยังมีความก้าวหน้าในการบูรณาการความหลากหลายรูปแบบเข้ากับ LLM ของตน นั่นคือความสามารถในการประมวลผลข้อมูลอื่นที่ไม่ใช่ข้อความลงใน LLM
มีโอเพ่นซอร์สโมเดล Qwen-Audio และ Qwen-Audio-Chat เพื่อการวิจัยและเชิงพาณิชย์
Qwen-Audio สามารถเข้าใจข้อความและเสียง รวมถึงคำพูดของมนุษย์ เสียงที่เป็นธรรมชาติ และดนตรี สามารถประมวลผลเสียงได้มากกว่า 30 งาน เช่น การถอดเสียงหลายภาษา การแก้ไขคำพูด และการวิเคราะห์คำบรรยายเสียง เวอร์ชันที่ได้รับการปรับแต่งการสนทนาอย่างละเอียดสามารถตรวจจับอารมณ์และน้ำเสียงในคำพูดของมนุษย์ได้
การผลักดันต่อเนื่องหลายรูปแบบต่อยอดมาจากความคิดริเริ่มก่อนหน้าของ Alibaba Cloud ในการใช้ โมเดล ภาษาวิสัยทัศน์ขนาดใหญ่ Qwen-VL แบบโอเพ่นซอร์ส และเวอร์ชันแชท Qwen-VL-Chat ที่สามารถเข้าใจข้อมูลภาพและดำเนินงานด้านภาพได้
โมเดล LLM แบบโอเพ่นซอร์ส ซึ่งรวมถึง Qwen-7B, Qwen-14B และ Qwen-VL รวมถึงเวอร์ชันที่ได้รับการปรับแต่งการสนทนา ได้รับการดาวน์โหลดรวมแล้วมากกว่า 1.5 ล้านครั้งบนชุมชนโมเดล AI แบบโอเพ่นซอร์สของ Alibaba Cloud ModelScope และ Hugging Face ตั้งแต่เดือนสิงหาคม ตามข้อมูลล่าสุดจาก Alibaba Cloud