Qwen2.5-Omni-7B ของ Alibaba Cloud ติดอันดับโมเดล AI บนใบหน้ากอด

บทความนี้ได้รับการอัปเดตเพื่อรวมรายการโมเดล AI ยอดนิยมและการดาวน์โหลดบนชุมชนโอเพ่นซอร์ส Hugging Face ในวันที่ 5 เมษายน
Qwen25-Omni-7B โมเดลมัลติโมดอลแบบครบวงจรในซีรีส์ Qwen ที่เปิดตัวโดย Alibaba Cloud เมื่อสัปดาห์ที่แล้ว อยู่ในอันดับต้น ๆ ของรายการโมเดล AI ในชุมชนโอเพ่นซอร์ส Hugging Face โดยมีการดาวน์โหลดมากกว่า 80,000 ครั้งในเวลาประมาณหนึ่งสัปดาห์นับตั้งแต่เปิดตัว
Qwen2.5-Omni-7B ได้รับการออกแบบมาอย่างมีเอกลักษณ์สําหรับการรับรู้แบบหลายรูปแบบที่ครอบคลุม สามารถประมวลผลอินพุตที่หลากหลาย รวมถึงข้อความ รูปภาพ เสียง และวิดีโอ ในขณะที่สร้างข้อความแบบเรียลไทม์และการตอบสนองด้วยคําพูดที่เป็นธรรมชาติ สิ่งนี้กําหนดมาตรฐานใหม่สําหรับ AI แบบมัลติโมดอลที่ปรับใช้ได้อย่างเหมาะสมที่สุดสําหรับอุปกรณ์เอดจ์ เช่น โทรศัพท์มือถือและแล็ปท็อป
แม้จะมีการออกแบบพารามิเตอร์ 7B ขนาดกะทัดรัด แต่ Qwen2.5-Omni-7B ก็มอบประสิทธิภาพที่เหนือชั้นและความสามารถหลายรูปแบบที่ทรงพลัง การผสมผสานที่ไม่เหมือนใครนี้ทําให้เป็นรากฐานที่สมบูรณ์แบบสําหรับการพัฒนาตัวแทน AI ที่คล่องตัวและคุ้มค่าซึ่งมอบคุณค่าที่จับต้องได้ โดยเฉพาะแอปพลิเคชันเสียงอัจฉริยะ ตัวอย่างเช่น โมเดลนี้สามารถใช้ประโยชน์เพื่อเปลี่ยนชีวิตโดยช่วยให้ผู้ใช้ที่มีความบกพร่องทางสายตานําทางสภาพแวดล้อมผ่านคําอธิบายเสียงแบบเรียลไทม์ ให้คําแนะนําในการทําอาหารทีละขั้นตอนโดยการวิเคราะห์ส่วนผสมของวิดีโอ หรือขับเคลื่อนบทสนทนาการบริการลูกค้าอัจฉริยะที่เข้าใจความต้องการของลูกค้าอย่างแท้จริง
ขณะนี้โมเดลนี้เป็นโอเพ่นซอร์สบน Hugging Face และ GitHub พร้อมการเข้าถึงเพิ่มเติมผ่าน Qwen Chat และ ModelScope ชุมชนโอเพนซอร์สของ Alibaba Cloud ในช่วงหลายปีที่ผ่านมา Alibaba Cloud ได้สร้างโมเดล AI เชิงกําเนิดมากกว่า 200 แบบเป็นโอเพนซอร์ส
ประสิทธิภาพสูงที่ขับเคลื่อนด้วยสถาปัตยกรรมที่เป็นนวัตกรรมใหม่
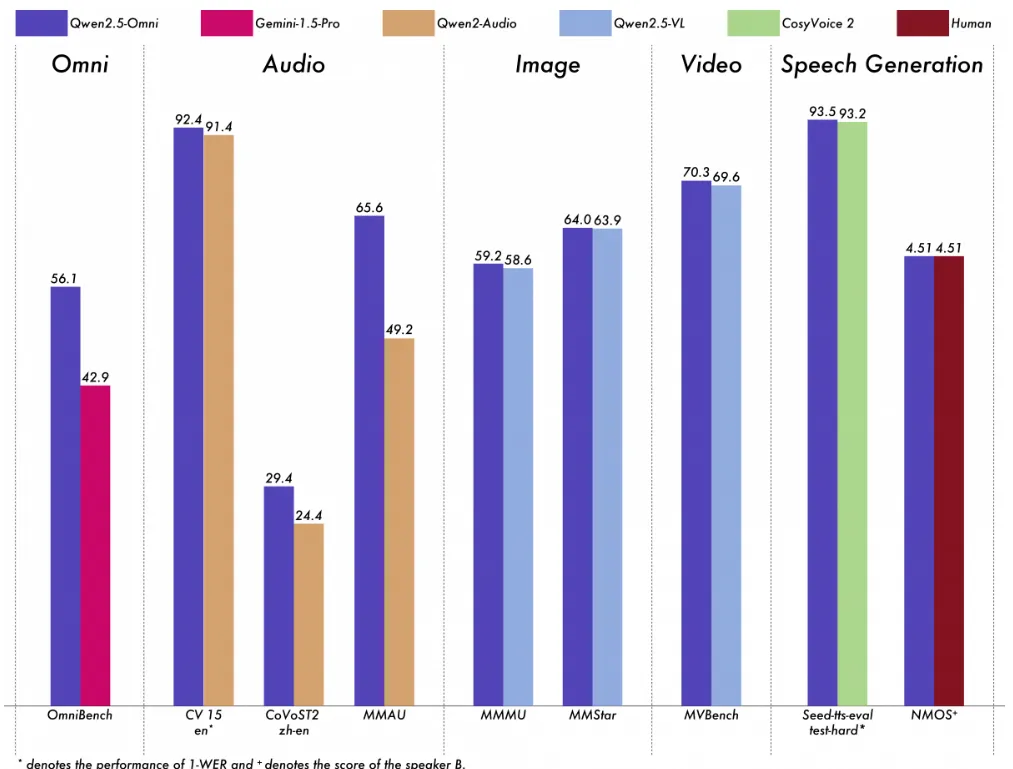
Qwen2.5-Omni-7B ให้ประสิทธิภาพที่โดดเด่นในทุกรูปแบบ แข่งขันกับโมเดลเดี่ยวเฉพาะทางที่มีขนาดใกล้เคียงกัน โดยเฉพาะอย่างยิ่ง มันกําหนดเกณฑ์มาตรฐานใหม่ในการโต้ตอบด้วยเสียงแบบเรียลไทม์ การสร้างคําพูดที่เป็นธรรมชาติและมีประสิทธิภาพ และการสอนด้วยเสียงพูดแบบ end-to-end ตามมา
ประสิทธิภาพและประสิทธิภาพสูงเกิดจากสถาปัตยกรรมที่เป็นนวัตกรรมใหม่ รวมถึงสถาปัตยกรรม Thinker-Talker ซึ่งแยกการสร้างข้อความ (ผ่าน Thinker) และการสังเคราะห์คําพูด (ผ่าน Talker) เพื่อลดการรบกวนระหว่างรูปแบบต่างๆ สําหรับผลลัพธ์คุณภาพสูง TMRoPE (Time-aligned Multimodal RoPE) เทคนิคการฝังตําแหน่งเพื่อซิงโครไนซ์อินพุตวิดีโอกับเสียงสําหรับการสร้างเนื้อหาที่สอดคล้องกัน และการประมวลผลสตรีมมิ่งแบบ Block-wise ซึ่งช่วยให้สามารถตอบสนองเสียงที่มีเวลาแฝงต่ําเพื่อการโต้ตอบด้วยเสียงที่ราบรื่น
ประสิทธิภาพที่โดดเด่นแม้จะมีขนาดกะทัดรัด
Qwen2.5-Omni-7B ได้รับการฝึกอบรมล่วงหน้าเกี่ยวกับชุดข้อมูลที่หลากหลายและหลากหลาย รวมถึงรูปภาพ-ข้อความ วิดีโอ-ข้อความ วิดีโอ-เสียง เสียง-ข้อความ และข้อมูลข้อความ เพื่อให้มั่นใจถึงประสิทธิภาพที่แข็งแกร่งในทุกงาน
ด้วยสถาปัตยกรรมที่เป็นนวัตกรรมใหม่และชุดข้อมูลที่ผ่านการฝึกอบรมล่วงหน้าคุณภาพสูงโมเดลจึงมีความเป็นเลิศในการปฏิบัติตามคําสั่งเสียงเพื่อให้ได้ระดับประสิทธิภาพที่เทียบได้กับการป้อนข้อความล้วน สําหรับงานที่เกี่ยวข้องกับการรวมรูปแบบต่างๆ เช่น งานที่ได้รับการประเมินใน OmniBench ซึ่งเป็นเกณฑ์มาตรฐานที่ประเมินความสามารถของโมเดลในการจดจํา ตีความ และให้เหตุผลผ่านอินพุตภาพ เสียง และข้อความ Qwen2.5-Omni บรรลุประสิทธิภาพที่ล้ําสมัย
Qwen2.5-Omni-7B ยังแสดงให้เห็นถึงประสิทธิภาพสูงในการทําความเข้าใจคําพูดที่มีประสิทธิภาพและความสามารถในการสร้างผ่านการเรียนรู้ในบริบท (ICL) นอกจากนี้ หลังจากการเพิ่มประสิทธิภาพการเรียนรู้แบบเสริมแรง (RL) Qwen2.5-Omni-7B แสดงให้เห็นถึงการปรับปรุงอย่างมีนัยสําคัญในความเสถียรของการสร้าง โดยลดการวางสมาธิผิดพลาด ข้อผิดพลาดในการออกเสียง และการหยุดชั่วคราวที่ไม่เหมาะสมระหว่างการตอบสนองของคําพูด
Alibaba Cloud เปิดตัว Qwen2.5 เมื่อเดือนกันยายนปีที่แล้ว และเปิดตัว Qwen2.5-Max ในเดือนมกราคม ซึ่งอยู่ในอันดับที่ 7 ใน Chatbot Arena ซึ่งตรงกับ LLM ที่เป็นกรรมสิทธิ์ชั้นนําอื่นๆ และแสดงให้เห็นถึงความสามารถที่ยอดเยี่ยม นอกจากนี้ Alibaba Cloud ยังเปิด Qwen2.5-VL และ Qwen2.5-1M แบบโอเพ่นซอร์สเพื่อเพิ่มความเข้าใจภาพและการจัดการการป้อนข้อมูลบริบทที่ยาวนาน
คุณอาจชอบเนื้อหานี้




เลือกชมสินค้ามากมาย และให้เราสั่งซื้อสินค้าให้คุณ
เนื้อหายอดนิยม




Qwen2.5-Omni-7B ของ Alibaba Cloud ติดอันดับโมเดล AI บนใบหน้ากอด

บทความนี้ได้รับการอัปเดตเพื่อรวมรายการโมเดล AI ยอดนิยมและการดาวน์โหลดบนชุมชนโอเพ่นซอร์ส Hugging Face ในวันที่ 5 เมษายน
Qwen25-Omni-7B โมเดลมัลติโมดอลแบบครบวงจรในซีรีส์ Qwen ที่เปิดตัวโดย Alibaba Cloud เมื่อสัปดาห์ที่แล้ว อยู่ในอันดับต้น ๆ ของรายการโมเดล AI ในชุมชนโอเพ่นซอร์ส Hugging Face โดยมีการดาวน์โหลดมากกว่า 80,000 ครั้งในเวลาประมาณหนึ่งสัปดาห์นับตั้งแต่เปิดตัว
Qwen2.5-Omni-7B ได้รับการออกแบบมาอย่างมีเอกลักษณ์สําหรับการรับรู้แบบหลายรูปแบบที่ครอบคลุม สามารถประมวลผลอินพุตที่หลากหลาย รวมถึงข้อความ รูปภาพ เสียง และวิดีโอ ในขณะที่สร้างข้อความแบบเรียลไทม์และการตอบสนองด้วยคําพูดที่เป็นธรรมชาติ สิ่งนี้กําหนดมาตรฐานใหม่สําหรับ AI แบบมัลติโมดอลที่ปรับใช้ได้อย่างเหมาะสมที่สุดสําหรับอุปกรณ์เอดจ์ เช่น โทรศัพท์มือถือและแล็ปท็อป
แม้จะมีการออกแบบพารามิเตอร์ 7B ขนาดกะทัดรัด แต่ Qwen2.5-Omni-7B ก็มอบประสิทธิภาพที่เหนือชั้นและความสามารถหลายรูปแบบที่ทรงพลัง การผสมผสานที่ไม่เหมือนใครนี้ทําให้เป็นรากฐานที่สมบูรณ์แบบสําหรับการพัฒนาตัวแทน AI ที่คล่องตัวและคุ้มค่าซึ่งมอบคุณค่าที่จับต้องได้ โดยเฉพาะแอปพลิเคชันเสียงอัจฉริยะ ตัวอย่างเช่น โมเดลนี้สามารถใช้ประโยชน์เพื่อเปลี่ยนชีวิตโดยช่วยให้ผู้ใช้ที่มีความบกพร่องทางสายตานําทางสภาพแวดล้อมผ่านคําอธิบายเสียงแบบเรียลไทม์ ให้คําแนะนําในการทําอาหารทีละขั้นตอนโดยการวิเคราะห์ส่วนผสมของวิดีโอ หรือขับเคลื่อนบทสนทนาการบริการลูกค้าอัจฉริยะที่เข้าใจความต้องการของลูกค้าอย่างแท้จริง
ขณะนี้โมเดลนี้เป็นโอเพ่นซอร์สบน Hugging Face และ GitHub พร้อมการเข้าถึงเพิ่มเติมผ่าน Qwen Chat และ ModelScope ชุมชนโอเพนซอร์สของ Alibaba Cloud ในช่วงหลายปีที่ผ่านมา Alibaba Cloud ได้สร้างโมเดล AI เชิงกําเนิดมากกว่า 200 แบบเป็นโอเพนซอร์ส
ประสิทธิภาพสูงที่ขับเคลื่อนด้วยสถาปัตยกรรมที่เป็นนวัตกรรมใหม่
Qwen2.5-Omni-7B ให้ประสิทธิภาพที่โดดเด่นในทุกรูปแบบ แข่งขันกับโมเดลเดี่ยวเฉพาะทางที่มีขนาดใกล้เคียงกัน โดยเฉพาะอย่างยิ่ง มันกําหนดเกณฑ์มาตรฐานใหม่ในการโต้ตอบด้วยเสียงแบบเรียลไทม์ การสร้างคําพูดที่เป็นธรรมชาติและมีประสิทธิภาพ และการสอนด้วยเสียงพูดแบบ end-to-end ตามมา
ประสิทธิภาพและประสิทธิภาพสูงเกิดจากสถาปัตยกรรมที่เป็นนวัตกรรมใหม่ รวมถึงสถาปัตยกรรม Thinker-Talker ซึ่งแยกการสร้างข้อความ (ผ่าน Thinker) และการสังเคราะห์คําพูด (ผ่าน Talker) เพื่อลดการรบกวนระหว่างรูปแบบต่างๆ สําหรับผลลัพธ์คุณภาพสูง TMRoPE (Time-aligned Multimodal RoPE) เทคนิคการฝังตําแหน่งเพื่อซิงโครไนซ์อินพุตวิดีโอกับเสียงสําหรับการสร้างเนื้อหาที่สอดคล้องกัน และการประมวลผลสตรีมมิ่งแบบ Block-wise ซึ่งช่วยให้สามารถตอบสนองเสียงที่มีเวลาแฝงต่ําเพื่อการโต้ตอบด้วยเสียงที่ราบรื่น
ประสิทธิภาพที่โดดเด่นแม้จะมีขนาดกะทัดรัด
Qwen2.5-Omni-7B ได้รับการฝึกอบรมล่วงหน้าเกี่ยวกับชุดข้อมูลที่หลากหลายและหลากหลาย รวมถึงรูปภาพ-ข้อความ วิดีโอ-ข้อความ วิดีโอ-เสียง เสียง-ข้อความ และข้อมูลข้อความ เพื่อให้มั่นใจถึงประสิทธิภาพที่แข็งแกร่งในทุกงาน
ด้วยสถาปัตยกรรมที่เป็นนวัตกรรมใหม่และชุดข้อมูลที่ผ่านการฝึกอบรมล่วงหน้าคุณภาพสูงโมเดลจึงมีความเป็นเลิศในการปฏิบัติตามคําสั่งเสียงเพื่อให้ได้ระดับประสิทธิภาพที่เทียบได้กับการป้อนข้อความล้วน สําหรับงานที่เกี่ยวข้องกับการรวมรูปแบบต่างๆ เช่น งานที่ได้รับการประเมินใน OmniBench ซึ่งเป็นเกณฑ์มาตรฐานที่ประเมินความสามารถของโมเดลในการจดจํา ตีความ และให้เหตุผลผ่านอินพุตภาพ เสียง และข้อความ Qwen2.5-Omni บรรลุประสิทธิภาพที่ล้ําสมัย
Qwen2.5-Omni-7B ยังแสดงให้เห็นถึงประสิทธิภาพสูงในการทําความเข้าใจคําพูดที่มีประสิทธิภาพและความสามารถในการสร้างผ่านการเรียนรู้ในบริบท (ICL) นอกจากนี้ หลังจากการเพิ่มประสิทธิภาพการเรียนรู้แบบเสริมแรง (RL) Qwen2.5-Omni-7B แสดงให้เห็นถึงการปรับปรุงอย่างมีนัยสําคัญในความเสถียรของการสร้าง โดยลดการวางสมาธิผิดพลาด ข้อผิดพลาดในการออกเสียง และการหยุดชั่วคราวที่ไม่เหมาะสมระหว่างการตอบสนองของคําพูด
Alibaba Cloud เปิดตัว Qwen2.5 เมื่อเดือนกันยายนปีที่แล้ว และเปิดตัว Qwen2.5-Max ในเดือนมกราคม ซึ่งอยู่ในอันดับที่ 7 ใน Chatbot Arena ซึ่งตรงกับ LLM ที่เป็นกรรมสิทธิ์ชั้นนําอื่นๆ และแสดงให้เห็นถึงความสามารถที่ยอดเยี่ยม นอกจากนี้ Alibaba Cloud ยังเปิด Qwen2.5-VL และ Qwen2.5-1M แบบโอเพ่นซอร์สเพื่อเพิ่มความเข้าใจภาพและการจัดการการป้อนข้อมูลบริบทที่ยาวนาน


