โมเดลการคิดล่าสุดของอาลีบาบามีความเป็นเลิศในการใช้เครื่องมือที่ปรับเปลี่ยนได้

อาลีบาบาได้เปิดตัวรูปแบบการให้เหตุผลล่าสุด: Qwen3-Max-Thinking ด้วยการขยายขนาดพารามิเตอร์ของโมเดลอย่างมีนัยสําคัญ (มากกว่า 1 ล้านล้านพารามิเตอร์) สําหรับการเรียนรู้แบบเสริมแรง Qwen3-Max-Thinking ช่วยเพิ่มประสิทธิภาพอย่างมากในหลายมิติ รวมถึงความรู้ข้อเท็จจริง การให้เหตุผลที่ซับซ้อน การติดตามคําสั่ง การจัดตําแหน่งตามความชอบของมนุษย์ และความสามารถของตัวแทน
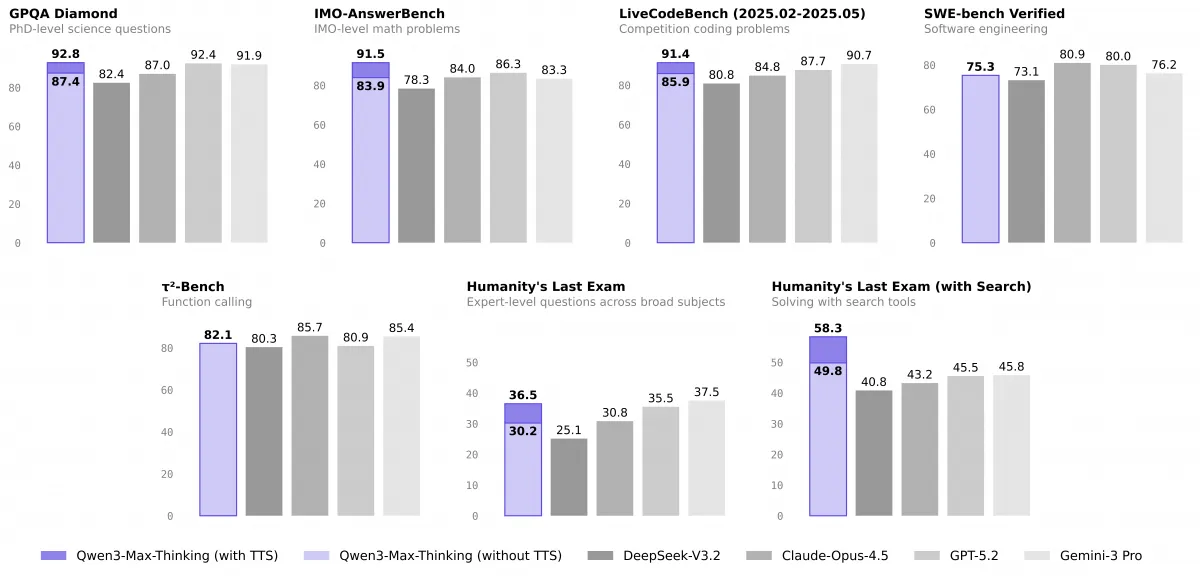
โมเดลนี้แสดงให้เห็นถึงประสิทธิภาพชั้นนําในการแข่งขันกับโมเดลขั้นสูง เช่น Claude Opus 4.5, Gemini 3 Pro และ GPT-5.2-Thinking-xhigh ในด้านต่างๆ รวมถึงการแก้คําถามด้านวิทยาศาสตร์ คณิตศาสตร์ และการเขียนโค้ด ตลอดจนการแก้คําถามระดับผู้เชี่ยวชาญในหัวข้อกว้างๆ ด้วยเครื่องมือค้นหา
ความสามารถที่โดดเด่นของ Qwen3-Max-Thinking เกิดจากนวัตกรรมที่โดดเด่นสองประการ หนึ่งคือความสามารถในการใช้เครื่องมือที่ปรับเปลี่ยนได้: โมเดลดึงข้อมูลอย่างชาญฉลาดและเรียกใช้ล่ามโค้ดในตัวตามความต้องการ ซึ่งช่วยปรับปรุงประสบการณ์ผู้ใช้อย่างมากโดยไม่ต้องเลือกเครื่องมือด้วยตนเอง นวัตกรรมอื่น ๆ คือเทคนิคการปรับขนาดเวลาทดสอบขั้นสูง: เทคนิคดังกล่าวช่วยเพิ่มประสิทธิภาพการให้เหตุผลได้อย่างมีนัยสําคัญทําให้แบบจําลองสามารถเหนือกว่าโมเดลชั้นนําอื่น ๆ ในเกณฑ์มาตรฐานการให้เหตุผลที่สําคัญ
ซึ่งแตกต่างจากวิธีการก่อนหน้านี้ที่ผู้ใช้ต้องเลือกเครื่องมือด้วยตนเองก่อนแต่ละงาน Qwen3-Max-Thinking จะเลือกแบบไดนามิกและใช้ประโยชน์จากความสามารถของการค้นหา หน่วยความจํา และล่ามโค้ดแบบบูรณาการระหว่างการสนทนา ซึ่งไม่จําเป็นต้องใช้ข้อกําหนดเครื่องมือที่ชัดเจน ความสําเร็จนี้เกิดขึ้นจากการฝึกอบรมอย่างกว้างขวางเกี่ยวกับงานที่หลากหลายโดยใช้ข้อเสนอแนะทั้งตามกฎและแบบจําลองหลังจากการปรับแต่งเบื้องต้นสําหรับการใช้เครื่องมือ
โดยเฉพาะอย่างยิ่งเครื่องมือค้นหาและหน่วยความจําของโมเดลช่วยลดภาพหลอนได้อย่างมีประสิทธิภาพปรับปรุงการเข้าถึงข้อมูลแบบเรียลไทม์และเปิดใช้งานการตอบสนองที่เป็นส่วนตัวมากขึ้นซึ่งปรับให้เหมาะกับความต้องการของผู้ใช้แต่ละราย นอกจากนี้ Code Interpreter ในตัวยังช่วยให้ผู้ใช้สามารถเรียกใช้ข้อมูลโค้ดหรือใช้เหตุผลเชิงคํานวณเพื่อแก้ปัญหาที่ซับซ้อนได้อย่างมีประสิทธิภาพมากขึ้น
นอกจากนี้ ทีมงานยังแนะนํากลยุทธ์การปรับขนาดเวลาทดสอบแบบหลายรอบที่สะสมประสบการณ์ กลไกนี้กลั่นกรองข้อมูลเชิงลึกที่สําคัญจากรอบการโต้ตอบก่อนหน้านี้ ทําให้แบบจําลองหลีกเลี่ยงการได้ข้อสรุปที่ทราบอีกครั้ง และมุ่งเน้นไปที่การแก้ไขความไม่แน่นอนที่เหลืออยู่แทน ด้วยเหตุนี้ วิธีการนี้จึงมีประสิทธิภาพบริบทที่สูงกว่าการอ้างอิงประวัติการโต้ตอบแบบดิบอย่างไร้เดียงสา ในขณะที่มีประสิทธิภาพเหนือกว่าวิธีการมาตรฐานอย่างสม่ําเสมอ (การสุ่มตัวอย่างแบบขนานและการรวม) ในราคาโทเค็นที่ใกล้เคียงกัน
Qwen3-Max-Thinking พร้อมใช้งานแล้วใน Qwen Chat ซึ่งผู้ใช้สามารถโต้ตอบกับโมเดลและได้รับประโยชน์จากความสามารถในการใช้เครื่องมือที่ปรับเปลี่ยนได้ API ของโมเดลยังมีอยู่ใน Model Studio แพลตฟอร์มการพัฒนา Generative AI ของอาลีบาบา
คุณอาจชอบเนื้อหานี้




เลือกชมสินค้ามากมาย และให้เราสั่งซื้อสินค้าให้คุณ
เนื้อหายอดนิยม




โมเดลการคิดล่าสุดของอาลีบาบามีความเป็นเลิศในการใช้เครื่องมือที่ปรับเปลี่ยนได้

อาลีบาบาได้เปิดตัวรูปแบบการให้เหตุผลล่าสุด: Qwen3-Max-Thinking ด้วยการขยายขนาดพารามิเตอร์ของโมเดลอย่างมีนัยสําคัญ (มากกว่า 1 ล้านล้านพารามิเตอร์) สําหรับการเรียนรู้แบบเสริมแรง Qwen3-Max-Thinking ช่วยเพิ่มประสิทธิภาพอย่างมากในหลายมิติ รวมถึงความรู้ข้อเท็จจริง การให้เหตุผลที่ซับซ้อน การติดตามคําสั่ง การจัดตําแหน่งตามความชอบของมนุษย์ และความสามารถของตัวแทน
โมเดลนี้แสดงให้เห็นถึงประสิทธิภาพชั้นนําในการแข่งขันกับโมเดลขั้นสูง เช่น Claude Opus 4.5, Gemini 3 Pro และ GPT-5.2-Thinking-xhigh ในด้านต่างๆ รวมถึงการแก้คําถามด้านวิทยาศาสตร์ คณิตศาสตร์ และการเขียนโค้ด ตลอดจนการแก้คําถามระดับผู้เชี่ยวชาญในหัวข้อกว้างๆ ด้วยเครื่องมือค้นหา
ความสามารถที่โดดเด่นของ Qwen3-Max-Thinking เกิดจากนวัตกรรมที่โดดเด่นสองประการ หนึ่งคือความสามารถในการใช้เครื่องมือที่ปรับเปลี่ยนได้: โมเดลดึงข้อมูลอย่างชาญฉลาดและเรียกใช้ล่ามโค้ดในตัวตามความต้องการ ซึ่งช่วยปรับปรุงประสบการณ์ผู้ใช้อย่างมากโดยไม่ต้องเลือกเครื่องมือด้วยตนเอง นวัตกรรมอื่น ๆ คือเทคนิคการปรับขนาดเวลาทดสอบขั้นสูง: เทคนิคดังกล่าวช่วยเพิ่มประสิทธิภาพการให้เหตุผลได้อย่างมีนัยสําคัญทําให้แบบจําลองสามารถเหนือกว่าโมเดลชั้นนําอื่น ๆ ในเกณฑ์มาตรฐานการให้เหตุผลที่สําคัญ
ซึ่งแตกต่างจากวิธีการก่อนหน้านี้ที่ผู้ใช้ต้องเลือกเครื่องมือด้วยตนเองก่อนแต่ละงาน Qwen3-Max-Thinking จะเลือกแบบไดนามิกและใช้ประโยชน์จากความสามารถของการค้นหา หน่วยความจํา และล่ามโค้ดแบบบูรณาการระหว่างการสนทนา ซึ่งไม่จําเป็นต้องใช้ข้อกําหนดเครื่องมือที่ชัดเจน ความสําเร็จนี้เกิดขึ้นจากการฝึกอบรมอย่างกว้างขวางเกี่ยวกับงานที่หลากหลายโดยใช้ข้อเสนอแนะทั้งตามกฎและแบบจําลองหลังจากการปรับแต่งเบื้องต้นสําหรับการใช้เครื่องมือ
โดยเฉพาะอย่างยิ่งเครื่องมือค้นหาและหน่วยความจําของโมเดลช่วยลดภาพหลอนได้อย่างมีประสิทธิภาพปรับปรุงการเข้าถึงข้อมูลแบบเรียลไทม์และเปิดใช้งานการตอบสนองที่เป็นส่วนตัวมากขึ้นซึ่งปรับให้เหมาะกับความต้องการของผู้ใช้แต่ละราย นอกจากนี้ Code Interpreter ในตัวยังช่วยให้ผู้ใช้สามารถเรียกใช้ข้อมูลโค้ดหรือใช้เหตุผลเชิงคํานวณเพื่อแก้ปัญหาที่ซับซ้อนได้อย่างมีประสิทธิภาพมากขึ้น
นอกจากนี้ ทีมงานยังแนะนํากลยุทธ์การปรับขนาดเวลาทดสอบแบบหลายรอบที่สะสมประสบการณ์ กลไกนี้กลั่นกรองข้อมูลเชิงลึกที่สําคัญจากรอบการโต้ตอบก่อนหน้านี้ ทําให้แบบจําลองหลีกเลี่ยงการได้ข้อสรุปที่ทราบอีกครั้ง และมุ่งเน้นไปที่การแก้ไขความไม่แน่นอนที่เหลืออยู่แทน ด้วยเหตุนี้ วิธีการนี้จึงมีประสิทธิภาพบริบทที่สูงกว่าการอ้างอิงประวัติการโต้ตอบแบบดิบอย่างไร้เดียงสา ในขณะที่มีประสิทธิภาพเหนือกว่าวิธีการมาตรฐานอย่างสม่ําเสมอ (การสุ่มตัวอย่างแบบขนานและการรวม) ในราคาโทเค็นที่ใกล้เคียงกัน
Qwen3-Max-Thinking พร้อมใช้งานแล้วใน Qwen Chat ซึ่งผู้ใช้สามารถโต้ตอบกับโมเดลและได้รับประโยชน์จากความสามารถในการใช้เครื่องมือที่ปรับเปลี่ยนได้ API ของโมเดลยังมีอยู่ใน Model Studio แพลตฟอร์มการพัฒนา Generative AI ของอาลีบาบา



