Alibaba Cloud เผยโฉม QwQ-32B: โมเดลการให้เหตุผลขนาดกะทัดรัดพร้อมประสิทธิภาพที่ล้ําสมัย

libaba Cloud ได้เปิดตัว QwQ-32B ซึ่งเป็นโมเดลการให้เหตุผลขนาดกะทัดรัดที่มีพารามิเตอร์เพียง 32 พันล้านพารามิเตอร์ ซึ่งให้ประสิทธิภาพเทียบเท่ากับโมเดลล้ําสมัยอื่นๆ ที่ใหญ่กว่า
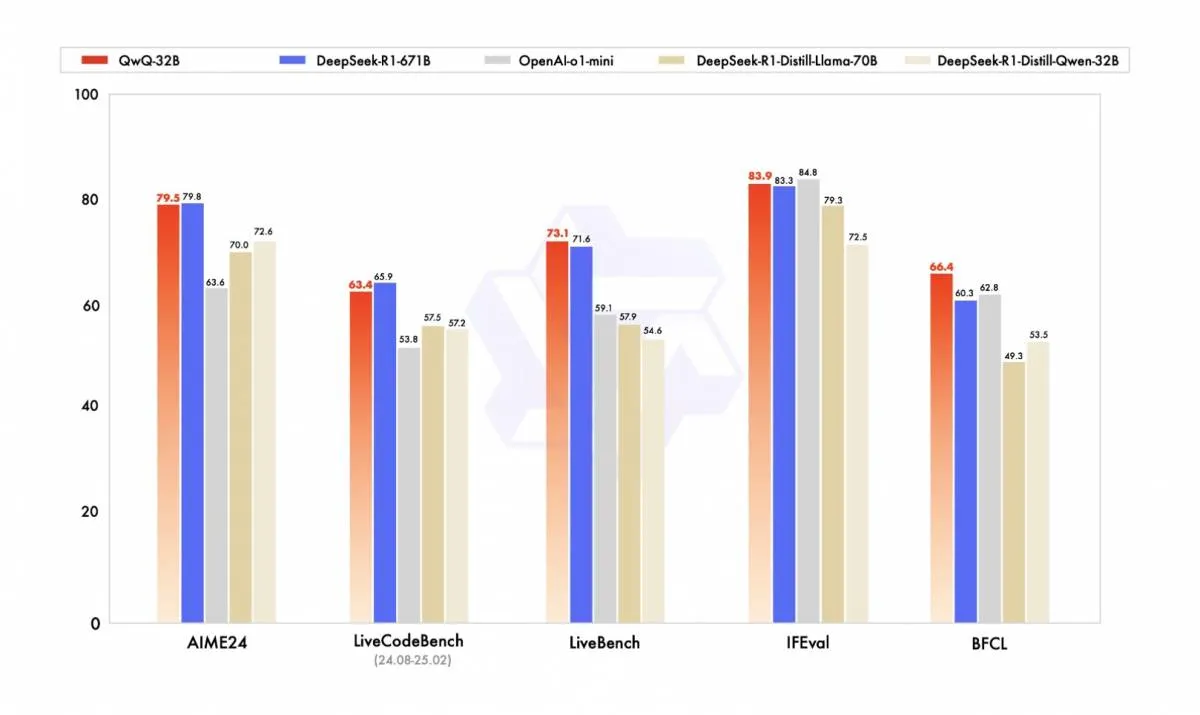
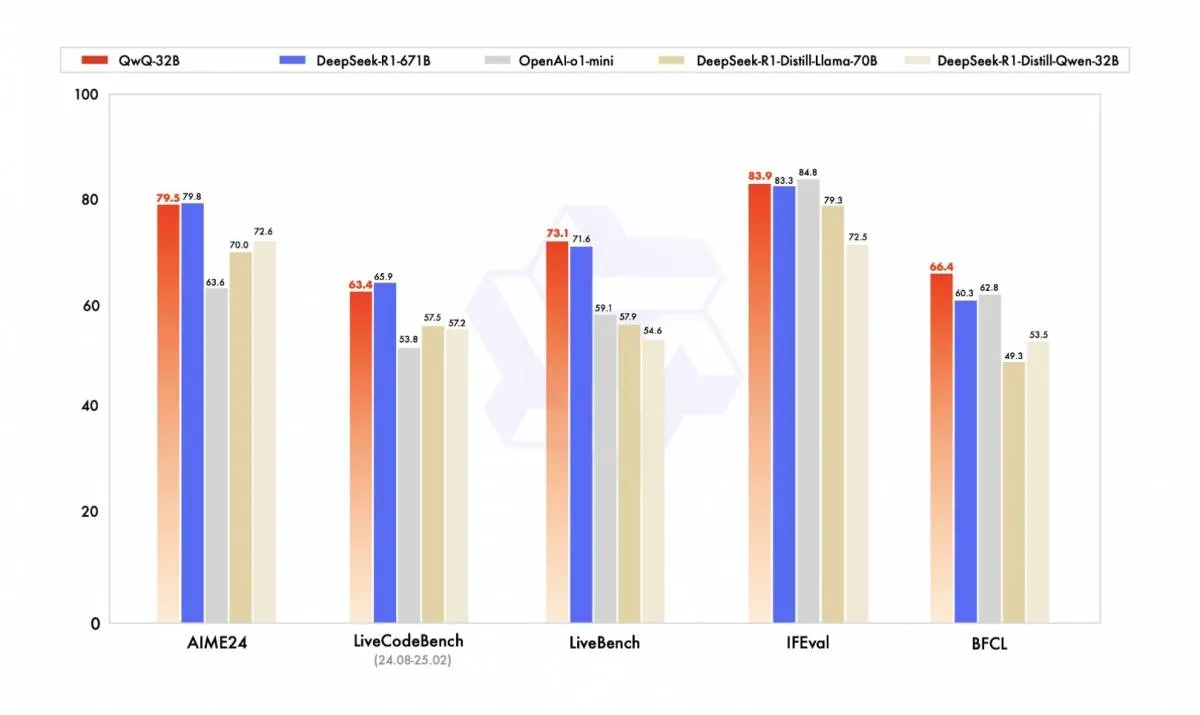
สร้างขึ้นบน Qwen2.5-32B ซึ่งเป็นโมเดลภาษาขนาดใหญ่ล่าสุดของ Alibaba Cloud ที่มีจํานวนพารามิเตอร์ที่แน่นอน QwQ-32B มีความเป็นเลิศในเกณฑ์มาตรฐานที่หลากหลาย รวมถึง AIME 24 (การให้เหตุผลทางคณิตศาสตร์), Live CodeBench (ความเชี่ยวชาญในการเขียนโค้ด), LiveBench (การปนเปื้อนของชุดทดสอบและการประเมินวัตถุประสงค์), IFEval (ความสามารถในการติดตามคําสั่ง) และ BFCL (ความสามารถในการเรียกใช้เครื่องมือและฟังก์ชัน)
การปรับขนาดการเรียนรู้แบบเสริมแรงเพื่อเพิ่มความสามารถในการให้เหตุผล
ประสิทธิภาพที่ยอดเยี่ยมของ QwQ-32B เน้นย้ําถึงพลังของ Reinforcement Learning (RL) ซึ่งเป็นเทคนิคหลักที่อยู่เบื้องหลังโมเดลเมื่อนําไปใช้กับโมเดลพื้นฐานที่แข็งแกร่ง เช่น Qwen2.5-32B ซึ่งได้รับการฝึกอบรมล่วงหน้าเกี่ยวกับความรู้โลกที่กว้างขวาง ด้วยการใช้ประโยชน์จากการปรับขนาด RL อย่างต่อเนื่อง QwQ-32B แสดงให้เห็นถึงการปรับปรุงที่สําคัญในการให้เหตุผลทางคณิตศาสตร์และความสามารถในการเขียนโค้ด
นอกจากนี้ โมเดลยังได้รับการฝึกอบรมโดยใช้รางวัลจากโมเดลรางวัลทั่วไปและตัวตรวจสอบตามกฎ ซึ่งช่วยเพิ่มความสามารถทั่วไป ซึ่งรวมถึงการปฏิบัติตามคําแนะนําที่ดีขึ้นการปรับให้สอดคล้องกับความชอบของมนุษย์และประสิทธิภาพของตัวแทนที่ดีขึ้น
การรวมความสามารถของตัวแทนเพื่อการให้เหตุผลขั้นสูง
ทีมวิจัยยังได้รวมความสามารถที่เกี่ยวข้องกับตัวแทนเข้ากับ QwQ-32B ทําให้สามารถคิดอย่างมีวิจารณญาณ ใช้เครื่องมืออย่างมีประสิทธิภาพ และปรับเหตุผลตามข้อเสนอแนะด้านสิ่งแวดล้อม ทีมงานยังสํารวจการผสานรวมตัวแทนกับ RL เพิ่มเติมเพื่อเปิดใช้งานการให้เหตุผลในระยะยาว โดยมีเป้าหมายเพื่อปลดล็อกความฉลาดที่มากขึ้นผ่านการปรับขนาดเวลาอนุมาน
QwQ-32B พร้อมใช้งานแล้วในรูปแบบโอเพ่นซอร์สบน Hugging Face และ Model Scope ภายใต้ใบอนุญาต Apache 2.0 ซึ่งอนุญาตให้ดาวน์โหลดได้ฟรี นอกจากนี้ยังสามารถเข้าถึงได้ผ่าน Qwen Chat ด้วยต้นทุนการปรับใช้ที่ลดลงอย่างมากโมเดลนี้จึงสามารถปรับใช้บนฮาร์ดแวร์ระดับผู้บริโภคได้อย่างมีประสิทธิภาพ
คุณอาจชอบเนื้อหานี้




เลือกชมสินค้ามากมาย และให้เราสั่งซื้อสินค้าให้คุณ




Alibaba Cloud เผยโฉม QwQ-32B: โมเดลการให้เหตุผลขนาดกะทัดรัดพร้อมประสิทธิภาพที่ล้ําสมัย

libaba Cloud ได้เปิดตัว QwQ-32B ซึ่งเป็นโมเดลการให้เหตุผลขนาดกะทัดรัดที่มีพารามิเตอร์เพียง 32 พันล้านพารามิเตอร์ ซึ่งให้ประสิทธิภาพเทียบเท่ากับโมเดลล้ําสมัยอื่นๆ ที่ใหญ่กว่า
สร้างขึ้นบน Qwen2.5-32B ซึ่งเป็นโมเดลภาษาขนาดใหญ่ล่าสุดของ Alibaba Cloud ที่มีจํานวนพารามิเตอร์ที่แน่นอน QwQ-32B มีความเป็นเลิศในเกณฑ์มาตรฐานที่หลากหลาย รวมถึง AIME 24 (การให้เหตุผลทางคณิตศาสตร์), Live CodeBench (ความเชี่ยวชาญในการเขียนโค้ด), LiveBench (การปนเปื้อนของชุดทดสอบและการประเมินวัตถุประสงค์), IFEval (ความสามารถในการติดตามคําสั่ง) และ BFCL (ความสามารถในการเรียกใช้เครื่องมือและฟังก์ชัน)
การปรับขนาดการเรียนรู้แบบเสริมแรงเพื่อเพิ่มความสามารถในการให้เหตุผล
ประสิทธิภาพที่ยอดเยี่ยมของ QwQ-32B เน้นย้ําถึงพลังของ Reinforcement Learning (RL) ซึ่งเป็นเทคนิคหลักที่อยู่เบื้องหลังโมเดลเมื่อนําไปใช้กับโมเดลพื้นฐานที่แข็งแกร่ง เช่น Qwen2.5-32B ซึ่งได้รับการฝึกอบรมล่วงหน้าเกี่ยวกับความรู้โลกที่กว้างขวาง ด้วยการใช้ประโยชน์จากการปรับขนาด RL อย่างต่อเนื่อง QwQ-32B แสดงให้เห็นถึงการปรับปรุงที่สําคัญในการให้เหตุผลทางคณิตศาสตร์และความสามารถในการเขียนโค้ด
นอกจากนี้ โมเดลยังได้รับการฝึกอบรมโดยใช้รางวัลจากโมเดลรางวัลทั่วไปและตัวตรวจสอบตามกฎ ซึ่งช่วยเพิ่มความสามารถทั่วไป ซึ่งรวมถึงการปฏิบัติตามคําแนะนําที่ดีขึ้นการปรับให้สอดคล้องกับความชอบของมนุษย์และประสิทธิภาพของตัวแทนที่ดีขึ้น
การรวมความสามารถของตัวแทนเพื่อการให้เหตุผลขั้นสูง
ทีมวิจัยยังได้รวมความสามารถที่เกี่ยวข้องกับตัวแทนเข้ากับ QwQ-32B ทําให้สามารถคิดอย่างมีวิจารณญาณ ใช้เครื่องมืออย่างมีประสิทธิภาพ และปรับเหตุผลตามข้อเสนอแนะด้านสิ่งแวดล้อม ทีมงานยังสํารวจการผสานรวมตัวแทนกับ RL เพิ่มเติมเพื่อเปิดใช้งานการให้เหตุผลในระยะยาว โดยมีเป้าหมายเพื่อปลดล็อกความฉลาดที่มากขึ้นผ่านการปรับขนาดเวลาอนุมาน
QwQ-32B พร้อมใช้งานแล้วในรูปแบบโอเพ่นซอร์สบน Hugging Face และ Model Scope ภายใต้ใบอนุญาต Apache 2.0 ซึ่งอนุญาตให้ดาวน์โหลดได้ฟรี นอกจากนี้ยังสามารถเข้าถึงได้ผ่าน Qwen Chat ด้วยต้นทุนการปรับใช้ที่ลดลงอย่างมากโมเดลนี้จึงสามารถปรับใช้บนฮาร์ดแวร์ระดับผู้บริโภคได้อย่างมีประสิทธิภาพ